お久しぶりです。
Platform Engineering Kaigi 2024 というカンファレンスがあって、運営として携わったのと、弊社の親会社(サイバーエージェント)でスポンサーもしてもらって、スポンサーブースの出展やスポンサー枠での登壇もしたので、今日はその振り返りです。
経緯
もともと Platform Engineering Meetup(PFEM) という勉強会の運営に関わっていたので、その流れでカンファレンスの運営にも関わらせてもらいました。
platformengineering.connpass.com
運営として何をやっていたか
当日の運営以外では、 PEK のウェブサイトの構築をしていました。
ぼくは、カンファレンス規模の運営には関わったことがなかったので、どうやってこのカンファレンスに貢献しようかと思っていたところ、ウェブサイトの構築をやるメンバーを募集していたので立候補しました。
本業で Frontend を書いたことはないのですが、自分のポートフォリオサイトを Astro + Cloudflare Pages で構築したことがあり、同じ技術スタックでWebサイトを構築するとのことだったので、チャレンジしてみることにしました。開発体制は3名のチームで、ぼくが一応リーダーをやらせていただきました。
サーバーサイドの JS/TS は仕事で日常的に書いてるのですが、 HTML と CSS にはかなり自信がなかったので正直結構不安でしたが、色々サポートしてもらいながらどうにか開発をやり切れました。Tailwind も初めて触りましたが、慣れるとなかなか便利だなと思いました。
結果として、「Web Frontend できます!」と自信を持って言えるほどではないですが、以前にくらべるとかなりフロントエンドへの苦手意識は減ったようなきがします。 普段はなかなか出会えない面白い機会と経験をいただけたのは本当に感謝です。
スポンサー出展
PEK ではスポンサーを募っていたので、サイバーエージェントでスポンサーの応募をしてもらいました。(弊社CTOが色々と計らってくださいました)
スポンサーの応募はかなりの数があったため抽選をしたのですが、運良く抽選にも当たり、スポンサー企業として協賛できることになりました。ちなみに運営メンバーだからという忖度はなかったです。(念の為)
スポンサー出展までの活動
2月頃からスポンサー応募に向けて動きだして、応募が決まってからはブース出展に向けて少しずつ準備を始めました。
ぼくはこれまで、ほとんど親会社の人たちと関わりがなかったため、 弊社CTO からサイバーエージェントの技術広報の方とPipeCD という CD ツールを開発している部署の人たちを繋いでもらいました。
個人的に印象的だったのは、技術広報の方から、 Platform Engineering についてネットで調べたけどまだよく分からないから、技術広報向けに簡単な勉強会をして欲しいというお願いをされたことでした。これから一緒にスポンサー出展などをしていくにあたり、しっかりと自分たちも理解を深めようとされている姿勢にとても頼もしさを感じて、サイバーエージェントすごいなと個人的に思っていました。
ブース出展にむけては、定期的にミーティングをして企画を固めて、PipeCD に関するクイズとInternal Developer Portal に関するアンケートの二つをやることで無事に着地し、当日も無事にブース出展することができました。
こちらもぼくが結構リードする感じで進めていたのですが、こういう経験をしたことがなかったのでかなり不安でした。しかし、会社の先輩や技術広報の方、 PipeCD チームの方の協力があって、うまく形にすることができてよかったです。
当日は、ぼくは運営の方が忙しくてブースの方は完全に任せきりになってしまいましたが、1日中ブースに立っていただいて本当に感謝でいっぱいです。
本日開催のPlatform Engineering Kaigi 2024 当社もスポンサーブースを設置しています!
— CyberAgentDevelopers (@ca_developers) 2024年7月9日
参加者の皆様に楽しんでいただける特別企画も用意しておりますので、ぜひ当社ブースまでお立ち寄りください🙌#PEK2024 pic.twitter.com/PhHS83W9Ji
登壇
PEK のプラチナ・ゴールドスポンサーには、スポンサーセッションの枠があり、サイバーエージェントはプラチナスポンサーだったため、登壇する権利がありました。
こちらも弊社CTO から、石川がやればいいじゃんと言っていただいたので、ぼくが登壇することになりました。
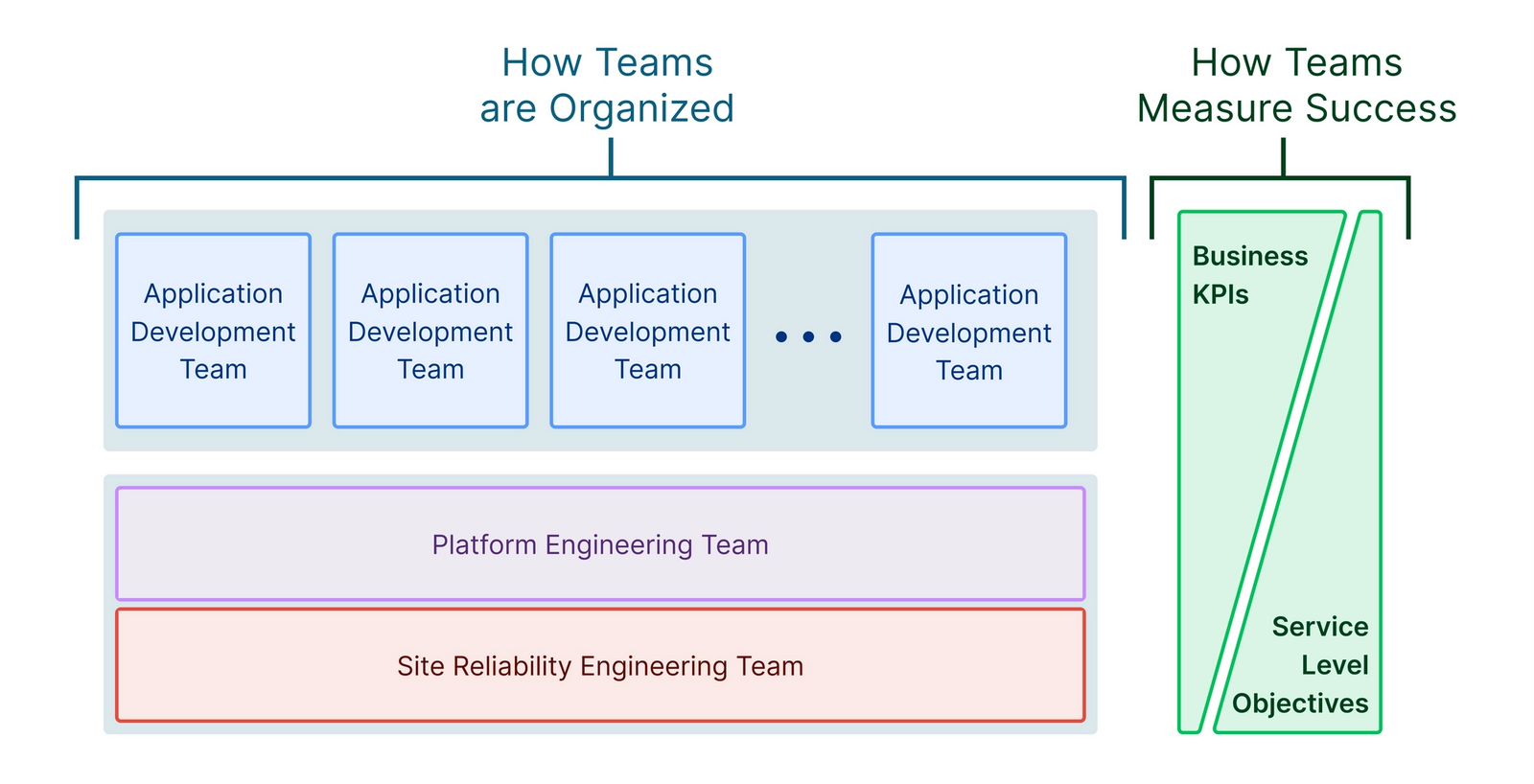
内容としては、弊社の Platform Engineering の事例について紹介させていただきました。 speakerdeck.com
弊社の取り組みをちゃんと整理して外部で発表してみたいと思っていたので、その夢がかなってよかったです。
実際、自分たちのこれまでの取り組みを、チームトポロジーの考え方に落とし込んで整理してみたのは、自分としても考えを整理したりチームトポロジーを再学習するとても貴重な機会になりました。
まとめ
Platform Engineering Kaigi というカンファレンスを通して、社内外の多くの人と関わり、たくさんの新しい経験をさせていただきました!
Platform Engineering Kaigi 2024 は無事終了しましたが、 PFEM や来年もPEKがあると思うので、引き続き貢献していけたらなと思っています。
そしてぼくをサポートしてくださったみなさまも本当にありがとうございました!
その他
PEKに向けて会社で記事を出してもらいました。 なかなかこういう機会はないので記念に貼っておきます。
弊社CTO との対談形式の記事 www.cyberagent.co.jp
カンファレンスの数日前に告知記事
7月9日(火)に開催される「Platform Engineering Kaigi 2024」に石川諒が登壇いたします。
— CyberAgentDevelopers (@ca_developers) 2024年7月4日
なお、当社はプラチナスポンサーとして協賛しています。ぜひ当社ブースまでお立ち寄りください🙌
限定ノベルティや特別クイズ企画を用意し皆様をお待ちしております!#PEK2024https://t.co/QcQcNcypDn